Reckoning: Part 3 — Caprock
Development without constraints isn't engineering.
Other posts in the series:
Last time, we looked at how JavaScript-based web development compounded serving errors on US public sector service sites, slowing down access to critical services. These defects are not without injury. The pain of accessing SNAP assistance services in California, Massachusetts, Maryland, Tennessee, New Jersey, and Indiana likely isn't dominated by the shocking performance of their frontends, but their glacial delivery isn't helping.
Waits are a price that developers ask users to pay and loading spinners only buy so much time.
Complexity Perplexity #
These SNAP application sites create hurdles to access because the departments procuring them made or green-lit inappropriate architecture choices. In fairness, those choices may have seemed reasonable given JavaScript-based development's capture of the industry.
Betting on JavaScript-based, client-side rendered architectures leads to complex and expensive tools. Judging by the code delivered over the wire, neither CalSAWS nor Deloitte understand those technologies well enough to operate them proficiently.
From long experience and a review of the metrics (pdf) the CalSAWS Joint Management Authority reports, it is plain as day that the level of organisational and cultural sophistication required to deploy a complex JavaScript frontend is missing in Sacramento:
It's safe to assume a version of the same story played out in Annapolis, Nashville, Boston, Trenton, and Indianapolis.
JavaScript-based UIs are fundamentally more challenging to own and operate because the limiting factors on their success are outside the data center and not under the control of procuring teams. The slow, flaky networks and low-end devices that users bring to the party define the envelope of success for client-side rendered UI.
This means that any system that puts JavaScript in the critical path starts at a disadvantage. Not only does JavaScript cost 3x more in processing power, byte-for-byte, than HTML and CSS, but it also removes the browser's ability to parallelise page loading. SPA-oriented stacks also preload much of the functionality needed for future interactions by default. Preventing over-inclusion of ancilliary code generally requires extra effort; work that is not signposted up-front or well-understood in industry.
This, in turn, places hard limits on scalability that arrive much sooner than with HTML-first progressive enhancement.
Consider today's 75-percentile mobile phone[1], a device like the Galaxy A50 or the Nokia G100:

This isn't much of a an improvement on the Moto G4 I recommended for testing in 2016, and it's light years from the top-end of the market today.

A device like this presents hard limits on network, RAM, and CPU resources. Because JavaScript is more expensive than HTML and CSS to process, and because SPA architectures frontload script, these devices create a cap on the scalability of SPAs.[2] Any feature that needs to be added once the site's bundle reaches the cap is in tension with every other feature in the site until exotic route-based code-splitting tech is deployed.
JavaScript bundles tend to grow without constraint in the development phase and can easily tip into territory that creates an unacceptable experience for users on slow devices.
Only bad choices remain once a project has reached this state. I have worked with dozens of teams surprised to have found themselves in this ditch. They all feel slightly ashamed because they've been led to believe they're the first; that the technology is working fine for other folks.[3] Except it isn't.
I can almost recite the initial remediation steps in my sleep.[4]
The remaining options are bad for compounding reasons:
- Digging into an experience that has been broken with JS inevitably raises a litany of issues that all need unplanned remediation.
- Every new feature on the backlog would add to, rather than subtract from, bundle size. This creates pressure on management as feature work grinds to a halt.
- Removing code from the bundle involves investigating and investing in new tools and deeply learning parts of the tower of JS complexity everyone assumed was "fine".
These problems don't generally arise in HTML-first, progressively-enhanced experiences because costs are lower at every step in the process:
- HTML and CSS are byte-for-byte cheaper for building an equivalent interface.
- "Routing" is handled directly by the browser and the web platform through forms, links, and REST. This removes the need to load code to rebuild it.
- Component definitions can live primarily on the server side, reducing code sent to the client.
- Many approaches to progressive enhancement (rather than "rehydration") use browser-native Web Components, eliminating both initial and incremental costs of larger, legacy-oriented frameworks.
- Because there isn't an assumption that script is critical to the UX, users succeed more often when it isn't there.
This model reduces the initial pressure level and keeps the temperature down by limiting the complexity of each page to what's needed.
Teams remediating underperforming JavaScript-based sites often make big initial gains, but the difficulty ramps up once egregious issues are fixed. The residual challenges highlight the higher structural costs of SPA architectures, and must be wrestled down the hard (read: "expensive") way.
Initial successes also create cognitive dissonance within the team. Engineers and managers armed with experience and evidence will begin to compare themselves to competitors and, eventually, question the architecture they adopted. Teams that embark on this journey can (slowly) become masters of their own destinies.
From the plateau of enlightenment, it's simple to look back and acknowledge that for most sites, the pain, chaos, churn, and cost associated with SPA technology stacks are entirely unnecessary. From that vantage point, a team can finally, firmly set policy.
Carrying Capacity #
Organisations that purchase and operate technology all have a base carrying capacity. The cumulative experience, training, and OpEx budgets of teams set the level.
Traditional web development presents a model that many organisations have learned to manage. The incremental costs of additional HTML-based frontends are well understood, from authorisation to database capacity to the intricacies of web servers
SPA-oriented frameworks? Not so much.
In practice, the complex interplay of bundlers, client-side routing mechanisms, GraphQL API endpoints, and the need to rebuild monitoring and logging infrastructure creates wholly unowned areas of endemic complexity. This complexity is experienced as a shock to the operational side of the house.
Before, developers deploying new UIs would cabin the complexity and cost within the data center, enabling mature tools to provide visibility. SPAs and client-side rendered UIs invalidate all of these assumptions. A common result is that the operational complexity of SPA-based technologies creates new, additive points of poorly monitored system failure — failures like the ones we have explored in this series.
This is an industry-wide scandal. Promoters of these technologies have not levelled with their customers. Instead, they continue to flog each new iteration as "the future" despite the widespread failure of these models outside sophisticated organisations.
The pitch for SPA-oriented frameworks like React and Angular has always been contingent — we might deliver better experiences if long chains of interactions can be handled faster on the client.
It's time to acknowledge this isn't what is happening. For most organisations building JavaScript-first, the next dollar spent after launch day is likely go towards recovering basic functionality rather than adding new features.
That's no way to run a railroad.
Should This Be An SPA? #
Public and private sector teams I consult with regularly experience ambush-by-JavaScript.
This is the predictable result of buying into frontend framework orthodoxy. That creed hinges on the idea that toweringly complex and expensive stacks of client-side JavaScript are necessary to deliver better user experiences.
But this has always been a contingent claim, at least among folks introspective enough to avoid suggesting JS frameworks for every site. Indeed, most web experiences should explicitly avoid both client-side rendered SPA UI and the component systems built to support them. Nearly all sites would be better off opting for progressive enhancement instead.
Doing otherwise is to invite the complexity fox into the OpEx henhouse. Before you know it, you're fighting with "SSR" and "islands" and "hybrid rendering" and "ISR" to get back to the sorts of results a bit of PHP or Ruby and some CSS deliver for a tenth the price.
So how can teams evaluate the appropriateness of SPAs and SPA-inspired frameworks? By revisiting the arguments offered by the early proponents of these approaches.
The entirety of SPA orthodoxy springs from the logic of the Ajax revolution. As a witness to, and early participant in, that movement, I can conclusively assert that the buzz around GMail and Google Maps and many other "Ajax web apps" was their ability to reduce latency for subsequent interactions once an up-front cost had been paid.
The logic of this trade depends, then, on the length of sessions. As we have discussed before, it's not clear that even GMail clears the bar in all cases.
The utility of the next quanta of script is intensely dependent on session depth.

Very few sites match the criteria for SPA architectures.
Questions managers can use to sort wheat from chaff:
- Does the average session feature more than 20 updates to, or queries against, the same subset of global data?
- Does this UI require features that naturally create long-lived sessions (e.g., chat, videoconferencing, etc.), and are those the site's primary purpose?
- Is there a reason the experience can't be progressively enhanced (e.g., audio mixing, document editing, photo manipulation, video editing, mapping, hardware interaction, or gaming)?
Answering these questions requires understanding critical user journeys. Flows that are most important to a site or project should be written down, and then re-examined through the lens of the marginal networks and devices of the user base.
The rare use-cases that are natural fits for today's JS-first dogma include:
- Document editors of all sorts
- Chat and videoconferencing apps
- Maps, geospatial, and BI visualisations
Very few sites should lead with JS-based, framework-centric development.
Teams can be led astray when sites include mutliple apps under a single umberella. The canonical example is WordPress; a blog reading experience for millions and a blog editing UI for dozens. Treating these as independent experiences with their own constraints and tech stacks is more helpful than pretending that they're actually a "single app". This is also the insight behind the "islands architecture", and transfers well to other contexts, assuming the base costs of an experience remain low.
The Pits #
DevTools product managers use the phrase "pit of success" to describe how they hope teams experience their tools. The alternative is the (more common) "pit of ignorance".
The primary benefit of progressive enhancement over SPAs and SPA-begotten frameworks is that they leave teams with simpler problems, closer to the metal. Those challenges require attention and focus on the lived experience, which can be remediated cheaply once identified.
The alternative is considerably worse. In a previous post I claimed that:
SPAs are "YOLO" for web development.
This is because an over-reliance on JavaScript moves responsibility for everything into the main thread in the most expensive way.
Predictably, teams whose next PR adds to JS weight rather than HTML and CSS payloads will find themselves in the drink faster, and with tougher path out.
What's gobsmacking is that so many folks have seen these bets go sideways, yet continue to participate in the pantomime of JavaScript framework conformism. These tools aren't delivering except in the breach, but nobody will say so.
And if we were only lighting the bonuses of overpaid bosses on fire through under-delivery, that might be fine. But the JavaScript-industrial-complex is now hurting families in my community trying to access the help they're entitled to.
It's not OK.
Aftermath #
Frontend is mired in a practical and ethical tar pit.
Not only are teams paying unexpectedly large premiums to keep the lights on, a decade of increasing JavaScript complexity hasn't even delivered the better user experiences we were promised.
We are not getting better UX for the escalating capital and operational costs. Instead, the results are getting worse for folks on the margins. JavaScript-driven frontend complexity hasn't just driven out the CSS and semantic-markup experts that used to deliver usable experiences for everyone, it is now a magnifier of inequality.
As previously noted, engineering is designing under constraint to develop products that serve users and society. The opposite of engineering is bullshitting, substituting fairy tales for inquiry and evidence.
For the frontend to earn and keep its stripes as an engineering discipline, frontenders need to internalise the envelope of what's possible on most devices.
Then we must take responsibility.
Next: The Way Out.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
3/4 of all devices are faster than this phone, which means 1/4 of phones are slower. Teams doing serious performance work tend to focus on even higher percentiles (P90, P95, etc.).
The Nokia G100 is by no means a hard target. Teams aspiring to excellence should look further down the price and age curves for representative compute power. Phones with 28nm-fabbed A53 cores are still out there in volume. ↩︎
One response to the regressive performance of the sites enumerated here is a version of "they're just holding it wrong; everybody knows you should use Server-Side Rendering (SSR) to paint content quickly".
Ignoring the factual inaccuracies undergirding SPA apologetics[5], the promised approaches ("SSR + hydration", "concurrent mode", etc.) have not worked.
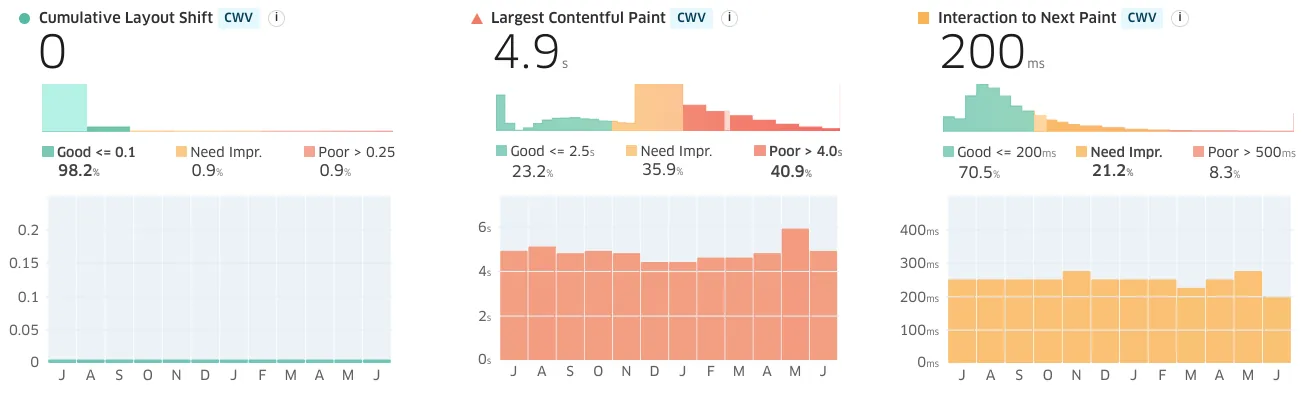
We can definitively see they haven't worked because the arrival of INP has shocked the body politic. INP has created a disturbance in the JS ecosystem because, for the first time, it sets a price on main-thread excesses backed by real-world data.
Teams that adopt all these techniques are still are not achieving minimally good results. This is likely why "React Server Components" exists; it represents a last-ditch effort to smuggle some of the most costly aspects of the SPA-based tech stack back to the server where it always belonged.
At the risk of tedious repetition, what these INP numbers mean is that these are bad experiences for real users. And these bad experiences can be laid directly at the feet of tools and architectures that promised better experiences.
Putting the lie to SPA theatrics doesn't require inventing a new, more objective value system. The only petard needed to hoist the React ecosystem into the stratosphere is its own sales pitch, which it has miserably and consistently failed to achieve in practice. ↩︎
The JavaScript community's omertà regarding the consistent failure of frontend frameworks to deliver reasonable results at acceptable cost is likely to be remembered as one of the most shameful aspects of frontend's lost decade.
Had the risks been prominently signposted, dozens of teams I've worked with personally could have avoided months of painful remediation, and hundreds more sites I've traced could have avoided material revenue losses.
Too many engineering leaders have found their teams beached and unproductive for no reason other than the JavaScript community's dedication to a marketing-over-results ethos of toxic positivity.
Shockingly, cheerleaders for this pattern of failure have not recanted, even when confronted with the consequences. They are not trustworthy. An ethical frontend practice will never arise from this pit of lies and half-truths. New leaders who reject these excesses are needed, and I look forward to supporting their efforts. ↩︎
The first steps in remediating JS-based performance disasters are always the same:
- Audit server configurations, including:
- Check caching headers and server compression configurations.
- Enable HTTP/2 (if not already enabled).
- Removing extraneous critical-path connections, e.g. by serving assets from the primary rather than a CDN host.
- Audit the contents of the main bundle and remove unneeded or under-used dependencies.
- Implement code-splitting and dynamic imports.
- Set bundle size budgets and implement CI/CD enforcement.
- Form a group of senior engineers to act as a "latency council".
- Require the group meet regularly to review key performance metrics.
- Charter them to approve all changes that will impact latency.
- Have them institute an actionable "IOU" system for short-term latency regression.
- Require their collective input when drafting or grading OKRs.
- Beg, borrow, or
stealbuy low-end devices for all product managers and follow up to ensure they're using them regularly.
There's always more to explore. SpeedCurve's Performance Guide and WebPageTest.org's free course make good next steps. ↩︎
- Audit server configurations, including:
Apologists for SPA architectures tend to trot out arguments with the form "nobody does X any more" or "everybody knows not to do Y" when facing concrete evidence that sites with active maintenance are doing exactly the things they have recently dissavowed, proving instead that not only are wells uncapped, but the oil slicks aren't even boomed.
It has never been true that in-group disfavour fully contains the spread of once-popular techniques. For chrissake, just look at the CSS-in-JS delusion! This anti-pattern appears in a huge fraction of the traces I look at from new projects today, and that fraction has only gone up since FB hipsters (who were warned directly by browser engineers that it was a terrible idea) finally declared it a terrible idea.
Almost none of today's regretted projects carry disclaimers. None of the frameworks that have led to consistent disasters have posted warnings about their appropriate use. Few boosters for these technologies even outline what they had to do to stop the bleeding (and there is always bleeding) after adopting these complex, expensive, and slow architectures.
Instead, teams are supposed to have followed every twist and turn of inscurtable faddism, spending effort to upgrade huge codebases whenever the new hotness changes.
Of course, when you point out that this is what the apologists are saying, no-true-Scotsmanship unfurls like clockwork.
It's irresponsibility theatre.
Consulting with more than a hundred teams over the past eight years has given me ring-side season tickets to the touring production of this play. The first few performances contained frission, some mystery...but now it's all played out. There's no paradox — the lies by omission are fully revealed, and the workmanlike retelling by each new understudy is as charmless as the last.
All that's left is to pen scathing reviews in the hopes that the tour closes for good. ↩︎